
Canny 边缘检测
参考:Canny 边缘检测
目标
Canny 边缘检测的概念
用于该函数的 OpenCV 函数 : cv.Canny()
理论
Canny Edge Detection 是一种流行的边缘检测算法。
1.这是一个多阶段算法,我们将介绍每个阶段。
2.Noise Reduction
由于边缘检测容易受到图像中杂色的影响,因此第一步是使用 5x5 高斯滤波器去除图像中的杂色。我们在前面的章节中已经看到了这一点。
3.求图像的强度梯度
然后,使用 Sobel 核在水平和垂直方向上过滤平滑后的图像,以获得水平方向的一阶导数 (Gx) 和垂直方向 (Gy).从这两张图片中,我们可以找到每个像素的边缘渐变和方向,如下所示:
$$Edge_Gradient ; (G) = \sqrt{G_x^2 + G_y^2} \ Angle ; (\theta) = \tan^{-1} \bigg(\frac{G_y}{G_x}\bigg)$$
渐变方向始终垂直于边缘。它四舍五入为代表垂直、水平和两个对角线方向的四个角之一。
4.Non-maximum Suppression
在获得梯度大小和方向后,对图像进行全面扫描以去除任何可能不构成边缘的不需要的像素。为此,在每个像素处,检查像素是否是其邻域中渐变方向的局部最大值。请看下面的图片:

点 A 位于边缘(垂直方向)。渐变方向垂直于边缘。点 B 和 C 位于梯度方向。因此,将点 A 与点 B 和 C 一起检查,以查看它是否形成局部最大值。如果是这样,则考虑将其用于下一阶段,否则,它将被抑制( 放零)。
简而言之,您得到的结果是具有 “thin edges” 的二进制图像。
5.磁滞阈值(Hysteresis Thresholding)
此阶段决定哪些 Edge 都是真正的 Edge,哪些不是。为此,我们需要两个阈值 minVal 和 maxVal。强度梯度大于 maxVal 的任何边都肯定是边,而低于 minVal 的边肯定是非边,因此被丢弃。位于这两个阈值之间的区域根据其连通性分类为边或非边。如果它们连接到“确定边缘”像素,则它们被视为边缘的一部分。否则,它们也会被丢弃。见下图:
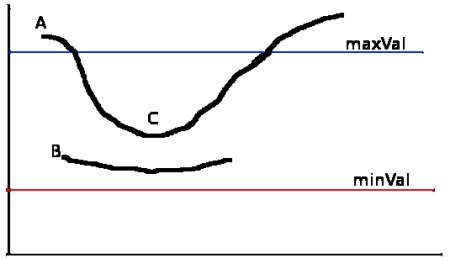
边 A 高于 maxVal,因此被视为 “sure-edge”。虽然边 C 低于 maxVal,但它连接到边 A,所以这也被认为是有效的边,我们得到了完整的曲线。但是边 B 虽然高于 minVal 并且与边 C 位于同一区域,但它没有连接到任何“确定边”,因此被丢弃。因此,我们必须相应地选择 minVal 和 maxVal 以获得正确的结果,这一点非常重要。
此阶段还根据边缘是长线的假设来删除小像素杂色。
因此,我们最终得到的是图像中的强边缘。
OpenCV 中的 Canny Edge Detection
OpenCV 将上述所有内容放在单个函数 cv.Canny() 中。我们将了解如何使用它。第一个参数是我们的输入图像。第二个和第三个参数分别是我们的minVal 和 maxVal。第四个参数是 aperture_size。它是用于查找图像梯度的 Sobel 核的大小。默认情况下,它是 3。最后一个参数是 L2gradient,它指定了求梯度幅度的方程。如果为 True,则使用上面提到的更准确的方程,否则使用此函数:$Edge_Gradient ; (G) = |G_x| + |G_y|$.默认情况下,它是 False。
1 | import numpy as np |
代码介绍
当然,我可以帮助你理解这个模型在做什么。让我们逐步解析代码,并解释每个部分的作用。
1. 导入必要的库
1 | import os |
os:用于文件路径操作。torch和torchvision:PyTorch 的核心库和计算机视觉工具包。Dataset和DataLoader:用于创建自定义数据集和加载数据。PIL.Image:用于图像处理。torch.nn:包含神经网络层和其他相关组件。
2. 自定义数据集类
1 | class QuickDrawDataset(Dataset): |
QuickDrawDataset类继承自torch.utils.data.Dataset。__init__方法初始化数据集,包括数据列表、数据转换和类别信息。__len__方法返回数据集的大小。__getitem__方法根据索引获取单个样本,包括图像和标签,并应用数据转换。
3. 定义数据转换
1 | transform = transforms.Compose([ |
transforms.Compose创建一个转换链,依次应用多个转换步骤。Resize:调整图像大小到 224x224。RandomHorizontalFlip:随机水平翻转图像以增加数据多样性。RandomRotation:随机旋转图像(最多 10 度)。ColorJitter:随机改变图像的颜色属性(亮度、对比度、饱和度、色调)。ToTensor:将图像转换为 PyTorch 张量。Normalize:标准化张量,使其具有零均值和单位标准差。
4. 创建数据集和数据加载器
1 | drawings = [f'data/images/cat_{i}.png' for i in range(100)] # 示例数据 |
drawings是一个包含图像路径的列表。train_data是一个字典列表,每个字典包含图像路径和标签。QuickDrawDataset实例化为train_dataset。DataLoader用于批量加载数据,并在训练时打乱数据。
5. 加载预训练的 ResNet-18 模型并修改最后一层
1 | model = models.resnet18(weights=None) # 使用本地预训练权重 |
models.resnet18初始化一个 ResNet-18 模型。model.fc.in_features获取原始全连接层的输入特征数。num_classes是数据集中的类别数量。nn.Linear创建一个新的全连接层,输出维度为num_classes,替换掉原来的全连接层。
6. 加载预训练权重
1 | pretrained_model_path = "resnet18-5c106cde.pth" |
- 检查预训练权重文件是否存在。
- 加载预训练权重。
- 创建一个新的状态字典,只包含除了
fc层以外的所有键值对。 - 更新现有的状态字典。
- 加载更新后的状态字典到模型中。
7. 冻结所有参数并解冻最后一层
1 | for param in model.parameters(): |
- 冻结所有参数,使它们在训练过程中不被更新。
- 解冻最后一层(新的全连接层),使其可以被训练。
8. 定义损失函数和优化器
1 | criterion = torch.nn.CrossEntropyLoss() |
CrossEntropyLoss用于多分类问题。Adam优化器用于优化模型的最后一层参数。
9. 训练循环
1 | device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") |
- 选择设备(GPU 或 CPU)并将模型移动到该设备上。
- 设置训练轮数。
- 在每个 epoch 中:
- 将模型设置为训练模式。
- 遍历数据加载器,获取批量数据。
- 将数据移动到设备上。
- 清零梯度。
- 前向传播,计算损失。
- 反向传播,更新参数。
- 累加损失。
- 打印每个 epoch 的平均损失。
10. 保存模型
1 | torch.save(model.state_dict(), 'resnet18_finetuned.pth') |
- 保存模型的状态字典到文件
resnet18_finetuned.pth。
总结
这个模型的主要工作流程如下:
- 数据准备:定义数据集和数据转换,创建数据加载器。
- 模型准备:加载预训练的 ResNet-18 模型,并修改最后一层以适应新的分类任务。
- 加载预训练权重:加载预训练权重,但排除
fc层。 - 冻结参数:冻结所有参数,只解冻最后一层。
- 定义损失函数和优化器:使用交叉熵损失和 Adam 优化器。
- 训练模型:进行多个 epoch 的训练,打印每个 epoch 的平均损失。
- 保存模型:训练完成后,保存模型的状态字典。
通过这些步骤,你可以利用预训练的 ResNet-18 模型进行迁移学习,训练它来识别你的特定数据集中的类别。
迁移学习
参考资料:基于PaddlePaddle的李宏毅机器学习——迁移学习
问题
什么是迁移学习呢?
1.假设现在要做猫和狗的分类器,我们需要一样标签数据告诉机器哪些是猫,哪些是狗。
2.同时,假设现在有一些与猫和狗没有直接关系的数据,这里说是没有直接关系,并不是说是完全没有关系。就是说有一些关系,但又不是直接相关的。
3.假设现在有自然界真实存在的老虎和大象的图片,那老虎和大象对分辨猫和狗会有帮助吗。
4.或者说我们有一些卡通动画中的猫和狗图像,但不是真实存在的,有没有帮助呢。
迁移学习把任务A开发的模型作为初始点,重新使用在为任务B开发模型的过程中。迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务。
迁移学习的概述

| 源数据(与任务没有直接关系) | 源数据(与任务没有直接关系) | ||
|---|---|---|---|
| 标记 | 未标记 | ||
| 目标数据 | 标记 | 微调、多任务学习 | 自学式学习 |
| 目标数据 | 未标记 | 域对抗训练、零次学习 | 自学式聚类 |
简单介绍:
微调(Fine-tuning):微调是指在一个预训练模型的基础上,使用特定任务的数据进一步训练模型的过程。这个过程通常包括调整模型参数以适应新的任务或数据集。
多任务学习(Multitask Learning):多任务学习是一种机器学习方法,它同时学习多个相关任务,并期望通过共享表示来提高所有任务的表现。这种方法假设不同任务之间存在某种形式的相关性,可以通过共同学习这些任务来改进每个单独任务的学习效果。
Domain-adversarial training(域对抗训练):这是一种迁移学习技术,通过训练一个模型来最小化源域和目标域之间的差异。它通常包括一个领域分类器,试图区分数据来自哪个领域,而特征提取器则尝试生成无法被该分类器区分开来的特征表示,以此来提高模型在目标领域的泛化能力。
Zero-shot learning(零次学习):零次学习是指模型能够对未见过的类别进行识别或分类的能力。这种情况下,模型没有直接接触过新类别的任何样本,但可以通过其他信息(如类别描述、属性等)来进行推断。
Self-taught learning(自学式学习):这是一种迁移学习的形式,其中使用大量未标记的数据来帮助提升目标任务的表现,即使这些数据与目标任务可能不是完全相关的。Rajat Raina, Alexis Battle, Honglak Lee, Benjamin Packer, Andrew Y. Ng 在2007年的ICML会议上发表的文章《Self-taught learning: transfer learning from unlabeled data》介绍了这种方法。
Self-taught Clustering(自学式聚类):这是Wenyuan Dai, Qiang Yang, Gui-Rong Xue, Yong Yu 在2008年ICML会议上提出的一种方法,它利用大量的未标记数据来进行聚类分析,并将学到的知识迁移到新的任务上。
代码定义了三个神经网络模块,它们都是用 PaddlePaddle 框架编写的。这三个模块分别是 FeatureExtractor、LabelPredictor 和 DomainClassifier。下面是对每个类的解释:
ppt
1 | class FeatureExtractor(nn.Layer): |
FeatureExtractor
FeatureExtractor 类用于从输入图像中提取特征。它接受一个形状为 [batch_size, 1, 32, 32] 的输入(表示一批灰度图像),并通过一系列卷积层、批归一化层、ReLU激活函数和最大池化层来提取特征。最终输出是一个形状为 [batch_size, 512] 的向量。
- 卷积层 (
nn.Conv2D):使用不同数量的滤波器对输入进行卷积操作。 - 批归一化层 (
nn.BatchNorm2D):对每一批数据进行归一化处理,以加速训练过程并提高模型稳定性。 - ReLU激活函数 (
nn.ReLU):引入非线性,使网络能够学习复杂的模式。 - 最大池化层 (
nn.MaxPool2D):通过取局部区域的最大值来减少特征图的空间尺寸,同时保留最重要的信息。 - 展平层 (
nn.Flatten):将多维张量展平成一维向量,以便后续的全连接层可以处理。
LabelPredictor
LabelPredictor 类用于预测图像中的动物类别。它接受一个形状为 [batch_size, 512] 的特征向量,并通过两个全连接层(nn.Linear)和 ReLU 激活函数来生成分类结果。最终输出是一个形状为 [batch_size, 10] 的向量,假设这里有 10 个不同的动物类别。
- 全连接层 (
nn.Linear):将输入向量映射到另一个向量空间。 - ReLU激活函数 (
nn.ReLU):在全连接层之间引入非线性。
DomainClassifier
DomainClassifier 类用于区分输入图像是手绘的还是真实的。它同样接受一个形状为 [batch_size, 512] 的特征向量,并通过多个全连接层、批归一化层和 ReLU 激活函数来生成二分类结果。最终输出是一个形状为 [batch_size, 1] 的向量,通常会通过一个 Sigmoid 函数将其转换为概率值。
- 全连接层 (
nn.Linear):与LabelPredictor类似,但这里有更多的层。 - 批归一化层 (
nn.BatchNorm1D):在一维数据上进行批归一化。 - ReLU激活函数 (
nn.ReLU):提供非线性变换。
总结
- FeatureExtractor 从图像中提取特征。
- LabelPredictor 使用这些特征来预测图像的类别。
- DomainClassifier 则使用相同的特征来判断图像是手绘的还是真实的。
这些组件可以组合起来构建更复杂的模型,例如用于域适应(domain adaptation)的任务,其中 FeatureExtractor 提供共享的特征表示,而 LabelPredictor 和 DomainClassifier 分别执行特定的任务。